A journey to Ontrack SaaS
Since Ontrack has been created some years and years ago, the product has grown in features and integrations. This can now be used from the collection of delivery metrics to really drive your automation using for example auto versioning on promotion or delivery metrics.
While it's always been very easy to install and setup Ontrack on local premises, it was always an idea of mine to provide one day a SaaS solution. After all, that'd be a natural fit in a CI/CD landscape where solutions are more and more available on the cloud as services.
This is now done, even if not launched officially yet (please contact me if you're interested, you can have early birds discounts).
In this article, I wanted to talk about my DevOps journey to create a SaaS service: its architecture, how it's deployed, how customers are onboarded and well, how I used Ontrack to help with the automation.
Along this journey to SaaS provisionng and automation, we'll talk about many things: Digital Ocean and managed resources, Kubernetes and Helm, Terraform and TFC (Terraform Cloud), Spring Boot, Stripe & Netlify. I'll try to keep the discussion high level to not make it too long to bear.
TL;DR
Terraform Cloud, Stripe, Netlify ... and Ontrack are great tools!
The target
Let's start with what Ontrack SaaS looks like once deployed for a customer.
As of now, Ontrack is deployed as a single-tenant stack a Digital Ocean managed Kubernetes cluster.
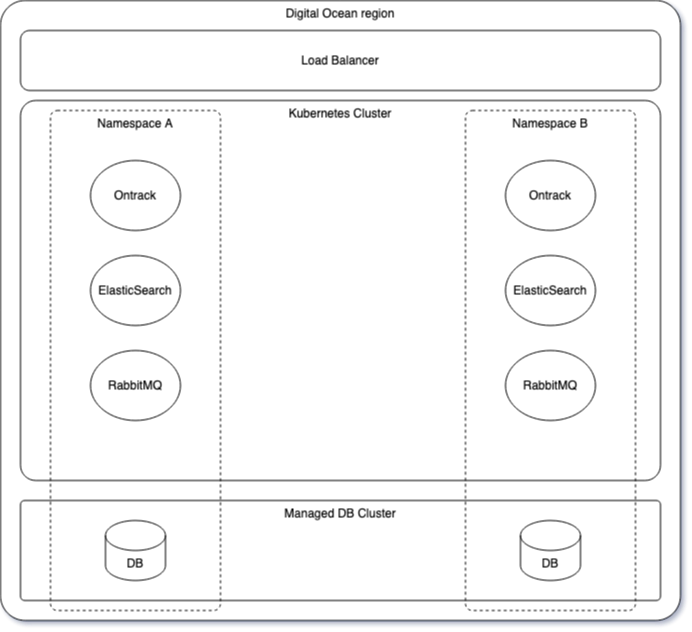
Each customer is assigned its own namespace and one database in a Postgresql managed cluster.
The namespace contains:
- Ontrack of course, a Spring Boot application, configured with some K8S secrets and configuration maps
- ElasticSearch, for the searches in Ontrack
- RabbitMQ, for the processing of asynchronous processes like GitHub ingestion or auto versioning on promotion
The application (Ontrack) is accessible from the outside through a managed ingress implemented by a DO load balancer. Each customer gets their own URL, like https://<instance>.ontrack.run.
Deploying one instance
The deployment of the K8S components is described by a Helm chart release and the overall instance (namespace + managed database + domain) is described by a Terraform module (ontrack-run-infra-do-cluster-instance).
Each instance (ie. customer) deployment is self-contained and implemented by a TFC workspace, pointing to the ontrack-run-infra-do-cluster-instance repository and setting up the specific variables (name of the instance, Ontrack version, target cluster, size of the database, limits of the application, license information, etc.).
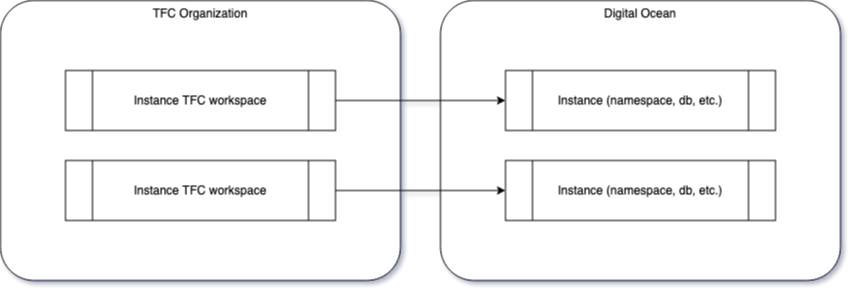
This structure provides three benefits:
- by pointing to one TF module, I can apply general updates on all instances
- variables are exhaustive - the TFC workspace is self-contained and does not depend on any other piece of infrastructure
- losing the TFC workspace does not affect the deployment
Now, how do I manage all the TFC workspaces?
Instance synchronization
Once I had defined that my unit of work for one instance would be a TFC workspace, I needed something to manage the list of workspaces and their variables.
I also new that I wanted to use Stripe to manage the customers and their subscriptions.
It became then natural to use some synchronization between all Stripe subscriptions and the TFC workspaces, leading to this very simple equation:
One Stripe subscription = One TFC workspace = One instance
A Stripe subscription is a link between a customer (name, email, payment means, VAT information, etc.) and a price in a product (like a plan).
Many Stripe entities allow the storage of metadata, which can be used by clients to get additional information. I decided to use this fact to drive the synchronization with TFC.
At price level (for example, the monthly payment for the Premium plan), I stored:
- some licensing information
- target cluster
At subscription level, I stored:
- the same of the instance for the customer
- optionally a deployment group (more on this later)
Then, I just needed a tool to synchronize Stripe with TFC. For this purpose, I created a small Spring Boot application called ontrack-pro-sync which regularly or on demand:
- creates a TFC workspace whenever a subscription is created
- updates a TFC workspace whenever a subscription is updated (plan changed for example)
- deletes a TFC workspace whenever a subscription is cancelled
Note that the deletion is tricky since deleting a TFC workspace does not destroy the associated resources. So, upon a cancellation, the ontrack-pro-sync launches first a destroy plan to remove the resources from Digital Ocean (database, namespace, DNS domain) and then only removes the workspace.
The ontrack-pro-sync tool is configured with:
- a list of clusters to target (staging, production for example)
- a list of Stripe products to manage
- a list of TFC variables to set for each product (size of the database or K8S limits for example)
This configuration can be held is a K8S configuration map.
I maintain two instances of the sync tool:
- a staging instance, defined by a Terraform module called
ontrack-run-do-pro-test - a production instance, defined by a Terraform module called
ontrack-run-do-pro-prod
Both modules maintain as code:
- the Helm-based deployment of the
synctool - the K8S configuration map
These two modules are run also by TFC as workspaces, so that whenever the source code changes (sync version, configuration, ...), the tool and its configuration are deployed and updated automatically in the target DO K8S cluster.
I'm using a generic mechanism to register all TFC workspaces using a root ontrack-run-do-workspaces workspace which is itself deployed from GitHub Actions (because, well, I don't like to set up things manually).
We finally have this kind of architecture:
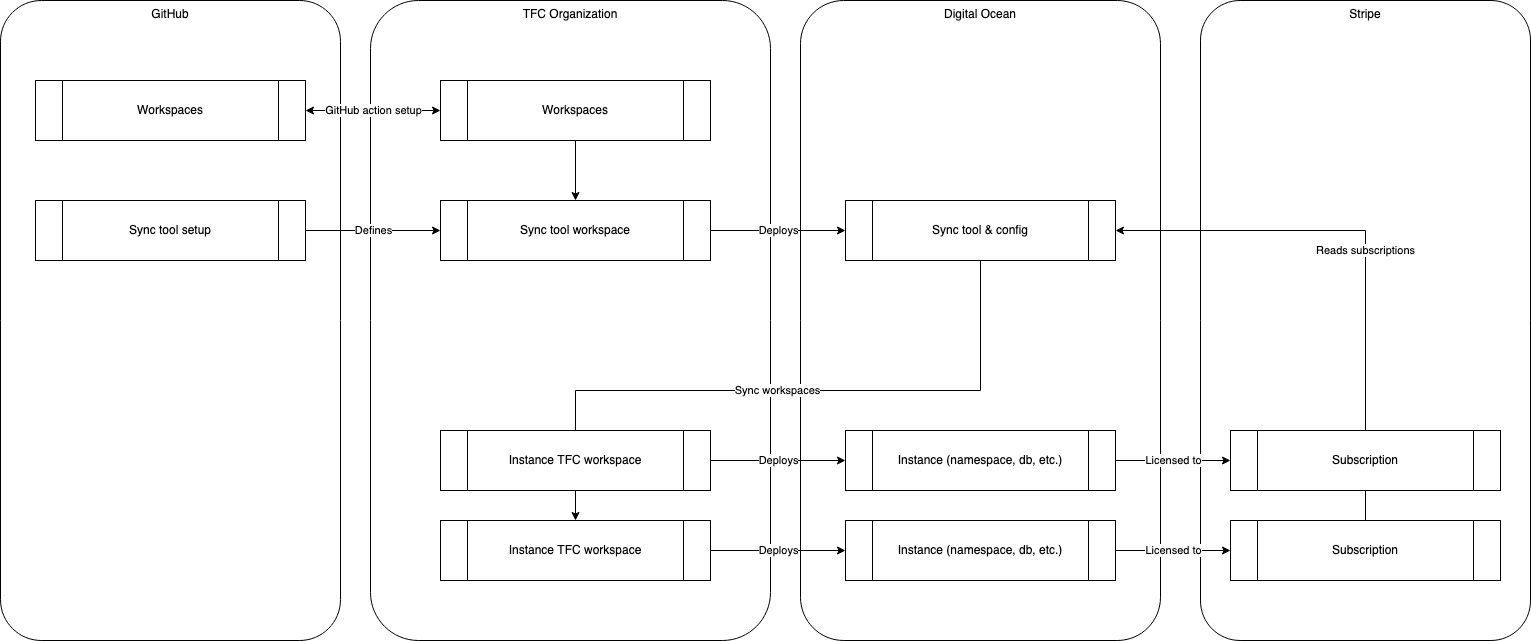
As a summary:
- we have a list of subscriptions in Stripe, linking customers to some plans, containing information about the instances to deploy
- a
synctool to convert these subscriptions into TFC workspaces - each TFC workspace is responsible to define the actual instance resources in Digital Ocean
Finally, we have one last moving part: the management of the subscriptions.
Customer portal
While it's possible to manage the Stripe subscriptions by hand, by using their dashboard UI, I wanted to provide a self-provisioning way to the customers. Using a portal, they could:
- sign up and create an account
- manage their subscriptions
The management of the subscriptions would include:
- the creation of a new instance: choosing the plan (size and payment calendar) and choosing the instance name
- upgrading an existing plan
- cancelling a plan
Since I did not want to spend too much time coding some web portal, I wanted to rely as much as possible on predefined services, and I chose:
- Stripe checkout & customer billing portal integrations
- Netlify identity
The few screens I needed to code would be done using Next.js and built and hosted by Netlify.
The interaction with Stripe from the portal is managed by the sync tool we mentioned above. Stripe has this very neat feature where you just open a checkout session (or a customer billing portal session) and you get a URL in return. From the portal, I just redirect to these URLs and let Stripe manage the rest. It's really awesome and allows me to rely 100% on Stripe to manage the payments, invoices, promotions, etc.
The interaction with sync is managed using Netlify serverless functions so that the client-side of the portal (your browser) is self-contained and interacts only with Netlify.
So, upon signing up in the portal, this looks like:
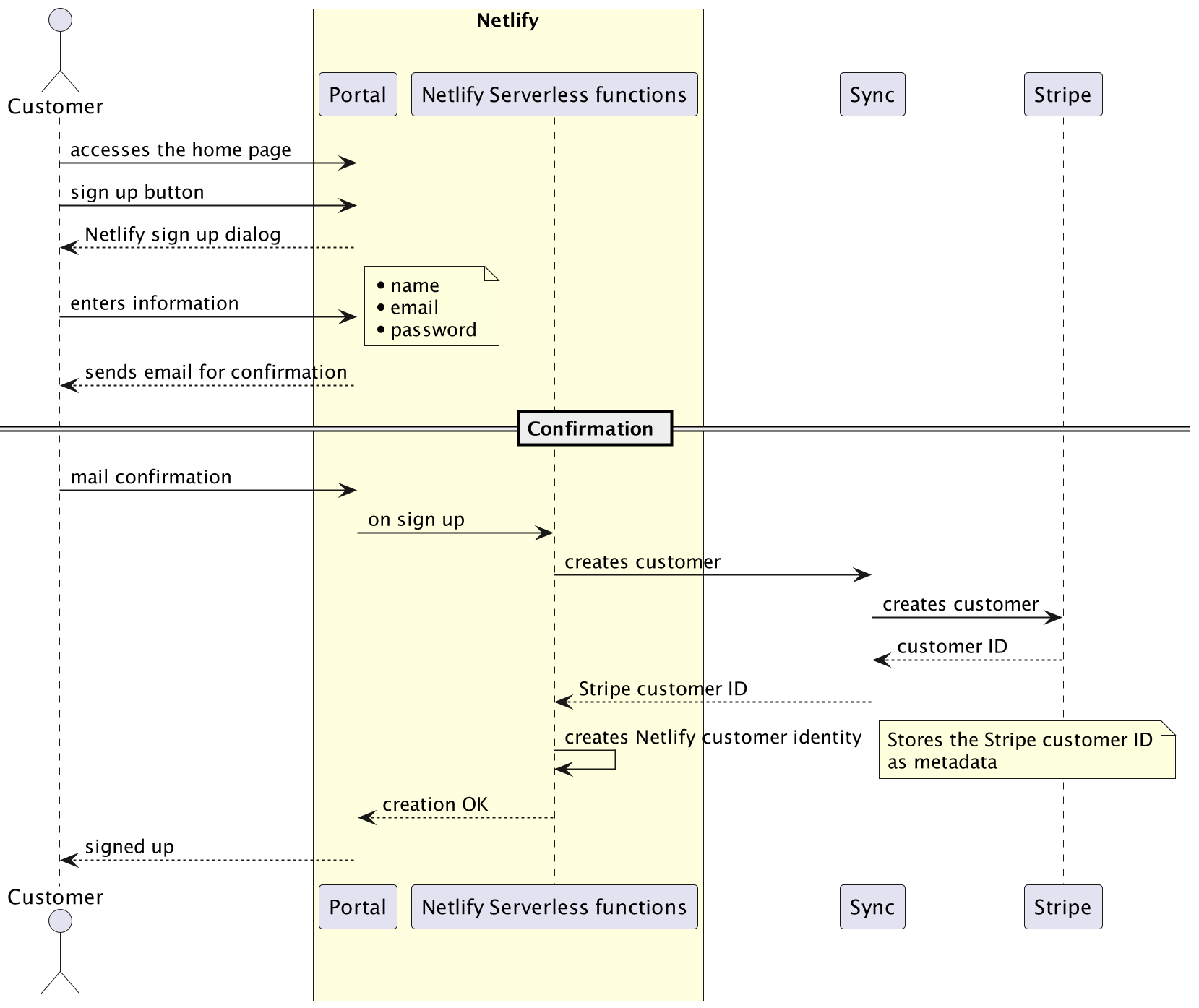
- a customer entity is created in Stripe
- a customer identity is created in Netlify and contains the Stripe customer ID as meta information
When the customer chooses to create a subscription, they are redirected to a page where they:
- choose a plan
- enter an instance name
The instance name is controlled for validity and unicity, and a Stripe checkout session is created, redirecting the customer to a Stripe-managed page for payment:
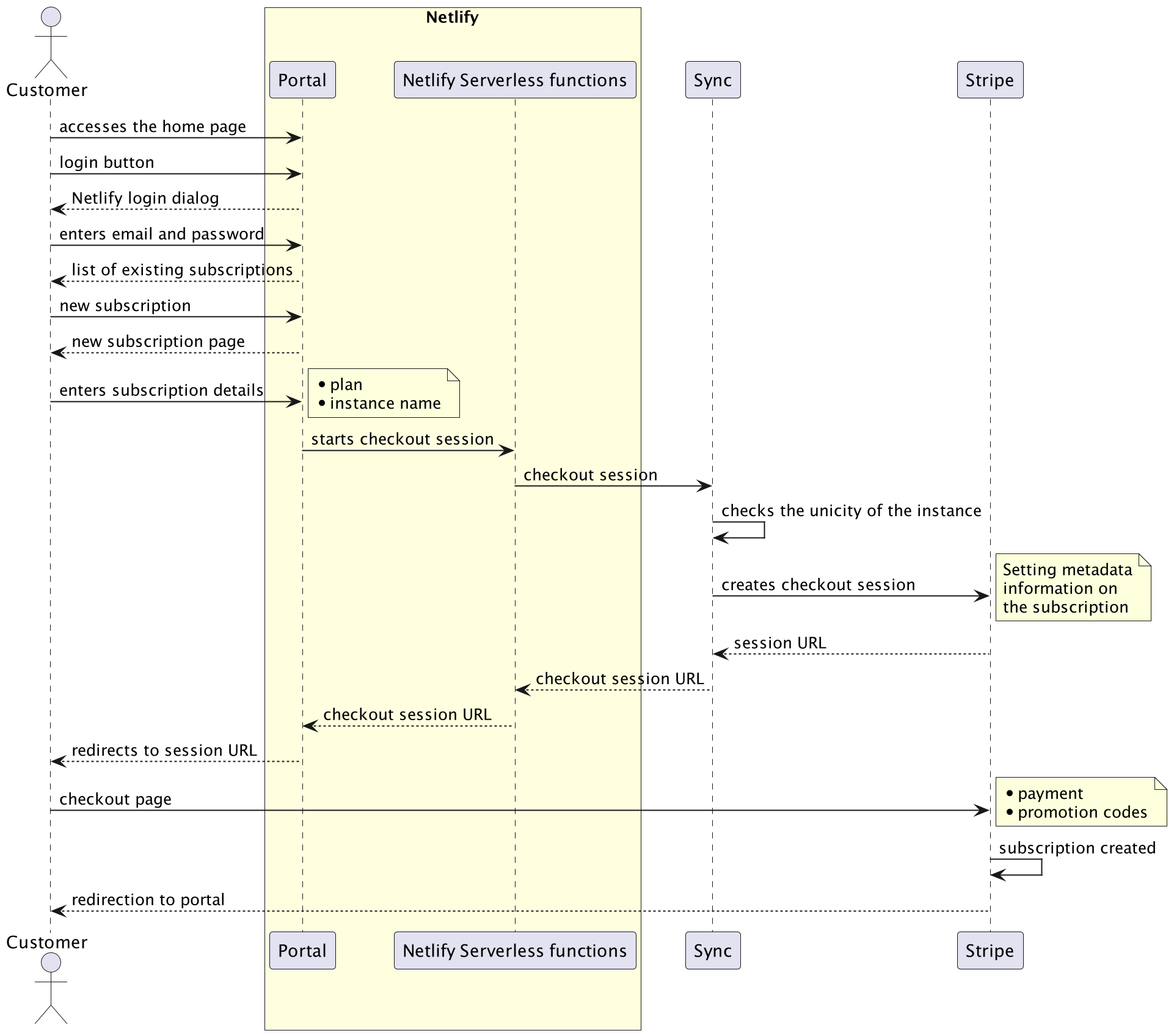
That's it! Whenever the subscription is created, the sync tool will then synchronize the Stripe subscriptions and create the corresponding TFC workspaces, which will in turn create the actual applications.
Ontrack versions
The Ontrack version deployed for a given instance is defined in the configuration for the sync tool:
clusters:
production-eu:
version: "4.4.0"
groups:
nemerosa:
version: "4.4.1"
# Rest of the configuration hiddenVersions can be managed at two levels:
- at cluster level - in the example above, version
4.4.0is used by default for all instances deployed into theproduction-eucluster - at group level - here, version
4.4.1is used for all instances belonging to thenemerosagroup
An instance is assigned to a group by setting some metadata at the Stripe subscription level.
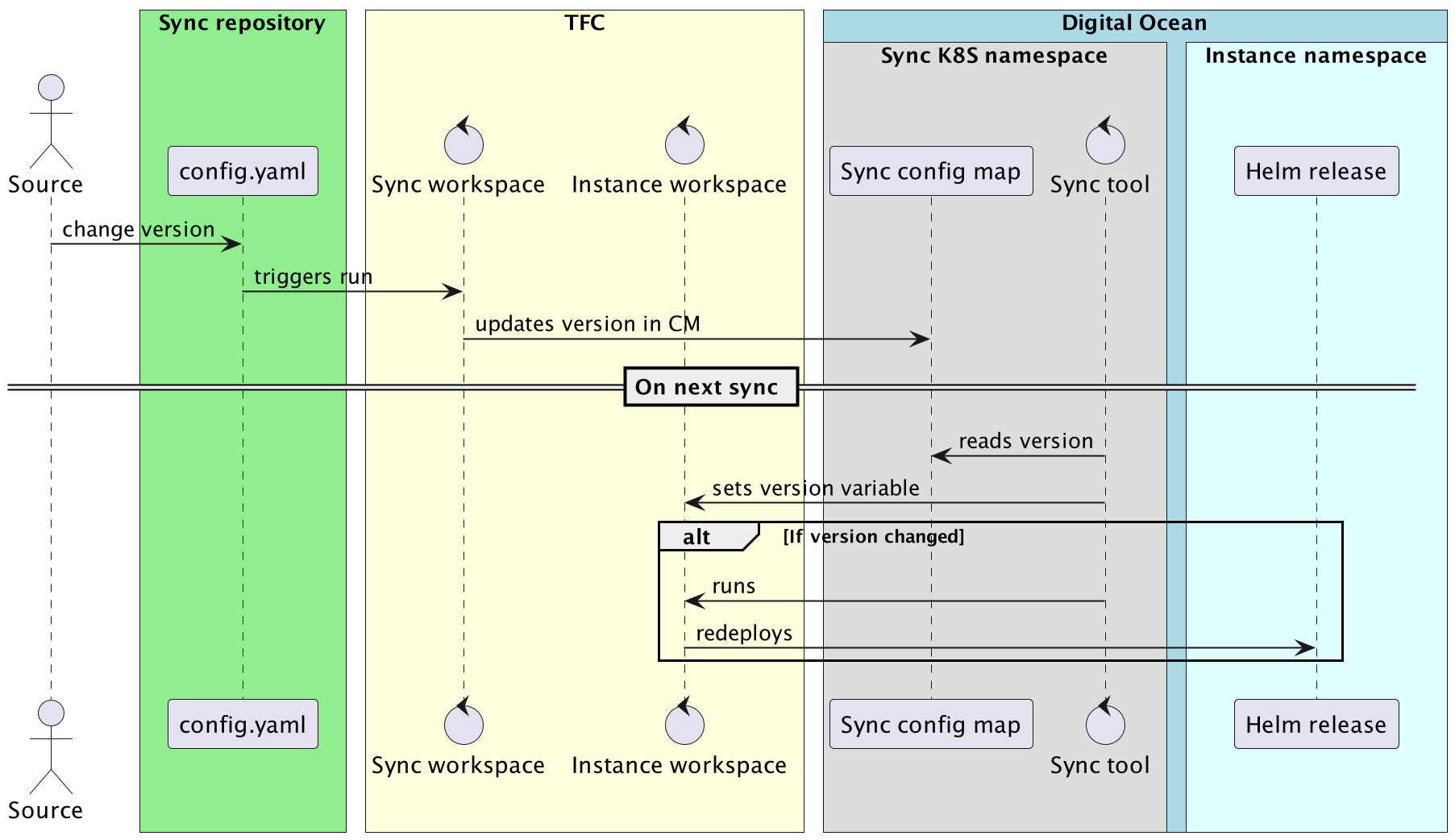
When the sync tool synchronizes a subscription with TFC, it gets the Ontrack version using:
- the subscription metadata if available
- the version at cluster level by default
If then sets the version as a TFC variable. In case this version changes, sync launches a run on the TFC workspace to force a redeployment.
This looks like:
Where is Ontrack?
In this whole setup, I'm using Ontrack itself:
- to track the
synctool versions:
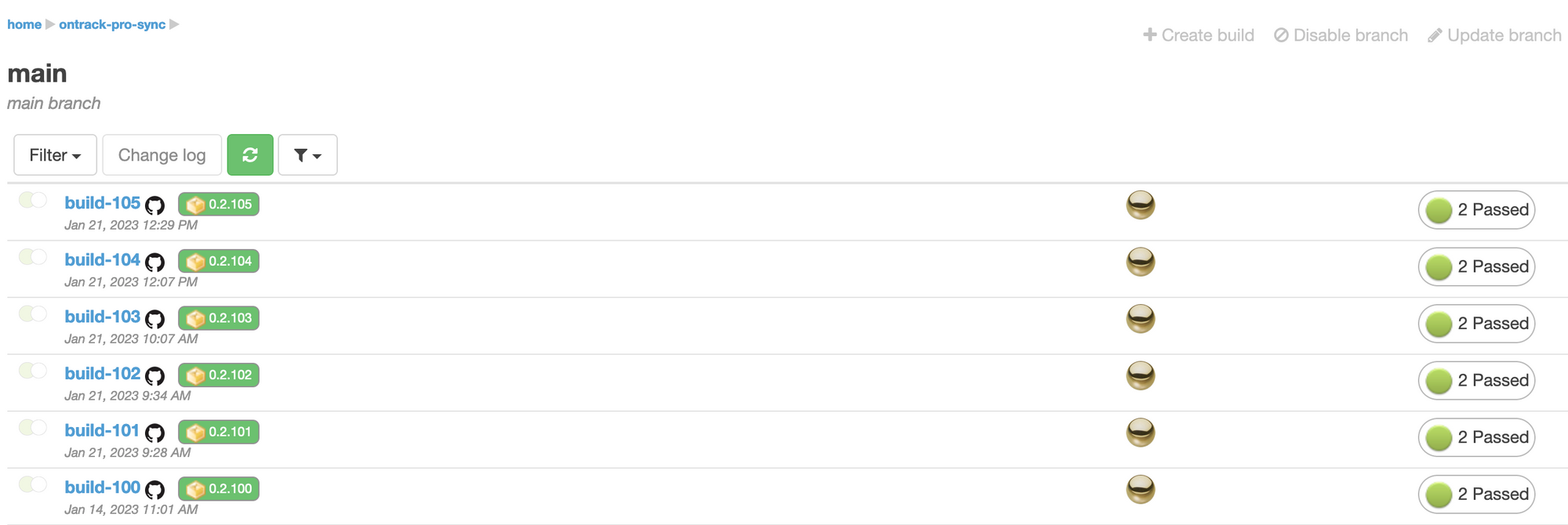
- to auto version the deployments of the
synctool in the staging and production environments:

- to auto version Ontrack upon a release in the sync tool configuration. For example, the Ontrack version of the
nemerosagroup is automatically upgraded upon aPRODUCTIONpromotion of the Ontrack application itself:

This auto versioning is itself defined as code in the different target repositories.
The Ontrack instance which is used to drive the updates around Ontrack SaaS is itself deployed using this solution (using a free Stripe subscription). Drinking my own beer...
Final words
I hope to have given you a good picture of how I chose to define and manage the Ontrack SaaS instances. Better solutions are likely to exist, and I'd love to hear about them. For me, it was a good compromise between saving time, using technology I know and out-of-the-shelf tools.
My goal was also clearly to define 100% of the setup as code (well, maybe 95%, since some stuff in Netlify and Stripe are still defined manually, like the price offering, the customer billing portal setup, etc.).
Of course, I could not describe every single detail in this article, like how the clusters are themselves defined, how they are provisioned and monitored. In short, I use the TFC workspace seed principle all the time, as soon as I need something deployed. It's become quite automatic for me to deploy things this way.
And whenever as possible, I'm using Ontrack to track the versions of the different components, and I'm using its "auto versioning on promotion" feature to smoothly and automatically propagate versions from one environment to the other.