MCP server from scratch - impressions
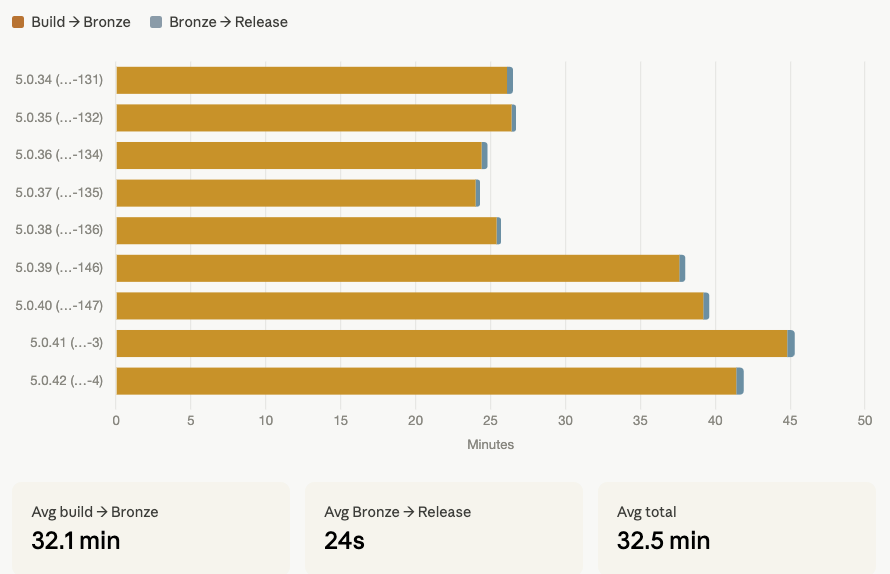
For builds that have been promoted to RELEASE, can you show me the time it takes to go from the build creation to the promotion? Can you also display the time it takes to go from Bronze to Release?
Last week, I wrote a piece about the links between having a good API and making MCP servers performant. Today, I'd like to dive a bit more into the details.
After some reading and some discussions, it had become obvious that creating a MCP server in front of Yontrack was a sensible path to follow. Data collected from any decent-sized CI/CD ecosystem is... rich, and there is no way a unique program can cover all use cases that users would have in mind.
Using an LLM to ask questions about the data in Yontrack was not only possible, but would open many possibilities for exploring more aspects of software deliveries.
So yes, here I was: in front of my screen, thinking about implementing an MCP server using the Yontrack API.
I knew upfront that I wanted to cover several aspects:
- Security first - how to open the Yontrack API to agents through an MCP server without compromising access to the data.
- Reliability - how to make agents understand how the Yontrack data is structured to create meaningful queries.
- Efficiency - how to reduce the overhead (network & token consumption) when calling the MCP server and, from there, the Yontrack API.
Well, never having experimented MCP servers on the implementation side, the answer was obvious: asking Claude Code directly 😄
I worked very (very) incrementally, from a basic proof of concept I could run directly from Claude Desktop to something I could quickly deploy using a Docker image and a Helm chart. Being who I am, everything was deliverable from the start and delivered through CI and CD. All in all, it took me a bit less than two hours (*****).
Already, one thing was obvious: it was abysmally slow. In Claude Desktop, I could see that it was doing a series of 1-N queries. For example, if I asked how long builds took on average for a given project, it would first get a list of builds, and then, for each build, get more information (like the time until the first promotion defining my "ready to go" state, what is called a "promotion" in Yontrack).
The initial list of tools made available by the MCP server was actually based on a first analysis made by Claude Code, using predefined queries for the Yontrack model (like "list of builds", "list of promotions for a build", etc.).
I found this a bit primitive since the model managed by Yontrack is very rich, and I thought this approach was restrictive, underperformant, and rigid. Could I make something better?
The answer came naturally after some thinking (going for a walk 🚶🌞🪻) and asking Claude again: Yontrack comes with a GraphQL API. This API is actually at the core of what Yontrack is: a way to query its data in a very flexible way. It's extensive (it has to be to make Yontrack what it is), well documented, and can be combined to fit exactly the needs of users in a very efficient way, limiting network calls. This was a perfect fit as a tool for an MCP server 😄
The rest was just a matter of tuning the MCP server instructions (**) to make any client understand that GraphQL was available and there to be used for non-trivial queries. Suddenly, the performance issue was gone; most of the time, only one query was needed to get the results that Claude needed to display.
Speaking of Claude, my next step was to integrate with https://claude.ai through a custom connector. This meant dealing with security. The way Claude integrates with a remote custom MCP server on the cloud is through a pure client-based OAuth authentication loop:
- Claude contacts the "well known endpoints" and forwards to the authentication page of the MCP server
- The user authenticates
- The MCP server returns a token to Claude
As usual, I didn't need to be an expert in OAuth: I just asked Claude Code, based on Claude.ai's own requirements, to enable authentication. In the end, my MCP server became an OAuth2 resource server in less than one hour, based on a single admin password.
That was good enough for the Claude part. Of course, it could be improved... but later (****). What about authentication to Yontrack? For now, I'm using a simple API token that I grant to the MCP server. I also configured the MCP server to use no GraphQL mutations, making it suitable for queries only.
That was it. The MCP server keeps being continuously tested and deployed together with my main instance of Yontrack, allowing me to ask high-level questions or create highly custom graphs, without having to code new APIs or screens.
What do I take away from this experience?
First of all, this approach to creating software is very... addictive 😄 The simple fact of not losing time typing boilerplate code makes you progress very fast and with confidence (*). I could simply focus on what really mattered: providing a new way to access Yontrack, and making it reliable and performant.
It allowed me to go beyond the boundaries of my individual knowledge (after all, I had never coded an MCP server before).
But one thing mattered to me throughout: I had to remain faithful to software delivery practices. Tests as requirements, implementation, continuous and frequent commits to the main branch, testing, publication. All this comes from a long habit of defining pipelines you can trust (*): if this passes, it's a go. Then, it was just a matter of plugging in Yontrack's auto-versioning to enable continuous deployment.
As for the use case itself, I still want to experiment more (***). In the very use case I've experimented with so far, the MCP server aspect complements existing "hard-coded" screens and APIs, it does not replace them: it opens your existing application (Yontrack in this case) to new use cases. In my own case, the GraphQL API is truly the key that unlocks these capabilities.
(*) Being able to trust your delivery pipelines is the ultimate tool that allows you to accelerate your deliveries with confidence.
(**) It still amazes me how much this tuning of agents or MCP servers boils down to a couple of paragraphs of text. One could think of this as a risk or a regression; I mostly see it as a refocusing on what we mean, rather than how things are done.
(***) Btw, if you're interested in using this MCP server, please contact me 😀
(****) Remember, just because an agent writes code for you doesn't mean you need to throw away 50+ years of coding practices.
(*****) No code was hurt by me in the process